Deep-research agents are easy to admire and almost impossible to compare.
One system uses a supervisor and worker fan-out. Another decomposes the query into a graph. A third expands perspectives in the style of STORM; a fourth trains its own search agent with reinforcement learning; a fifth just asks a stronger model to write the report after a single retrieval pass. Then the papers arrive with confident architecture claims — and the model, the tool stack, the query set, the retry policy, and the citation layer have all changed at the same time. When five variables move together, no result can be attributed to any one of them.
This benchmark fixes that. It holds the model family, the tool layer, the query manifest, and the judging protocol as constant as a research budget allows, and varies only the orchestration architecture. The question is deliberately narrow: once a deep-research system has enough retrieval and synthesis structure to be competent, how much does the architecture actually matter?
The short answer surprised me. Six different architectures finished in a statistical dead heat for the top. The base model mattered about twice as much as any of them. And the highest-scoring system of all was citing 62.9% fake citations that the judges happily rewarded.
Controlled benchmark at a glance
What the deep-research study measured
Architecture
Six GPT-4o pipelines formed a top cluster
Once a system has competent retrieval and synthesis structure, more elaborate orchestration stops buying reliable gains. The cluster is power-justified equivalence, not a single winner.
Model scale
Model scale dominated the architecture effects
Architecture had real, measurable effects — but base-model capability mattered several times more in this setup.
Judge distillation
DR-Judge worked for the easy cases only
The small judge missed its pre-registered κ ≥ 0.7 target. It is a triage layer for undisputed verdicts, not a panel replacement.
RL training
Reward design mattered more than RL itself
Rubric-judge-supervised GRPO did not lift the 7B policy; outcome-supervised RL (DeepResearcher-7B) did. A bounded result about reward design, not an anti-RL claim.
Limits
The retrieval bottleneck is inferred, not demonstrated — the tool layer was held constant, so no intervention isolates retrieval. Report quality, citation provenance, and factuality are all scored by LLMs, with no human reference-rating pilot. Substantive-dimension judge agreement is weak (Krippendorff α 0.105-0.135). The 90-query manifest is English-language only.
Experiment design
The whole benchmark in one control loop
The benchmark fixes the model family, tool layer, query manifest, and judging protocol, then varies only the orchestration architecture — so a quality difference can be attributed to one variable instead of five moving at once.
Fixed inputs
1Hold the comparison still
The benchmark fixes the query manifest, tool layer, retry behavior, and scoring protocol so architecture is not being compared through a fog of unrelated changes.
Varied systems
2Change the research architecture
The systems under test span single-pass retrieval, iterative RAG, supervisor fan-out, STORM-style perspectives, graph decomposition, beam search, local 7B baselines, and RL agents.
Judged outputs
3Score with a panel, not a vibe
A three-frontier-judge panel scores reports across nine rubric dimensions, then the analysis checks agreement, equivalence, run variance, and judge failure modes.
Audited claims
4Inspect the source layer
The work audits citation provenance, tests a C0 verification cache, reports DR-Judge limits, and keeps the P12 GRPO result negative rather than smoothing it away.
The setup, briefly
The study compares 13 architectures across three families, all running against the same 90-query manifest and the same tool layer (web search, the Semantic Scholar and arXiv APIs, page extraction, a shared retry policy). Nine are GPT-4o pipelines spanning the usual design space — a single-pass baseline, iterative RAG, a supervisor fan-out, a topic-mining loop, STORM-style perspective expansion, hierarchical width-and-depth, reactive interleaving, graph decomposition, and beam search over outlines. Two are local 7B systems: a plain baseline and one RL-trained end-to-end for research. Two more were added afterward: a canonical ReAct loop, and a 7B agent I trained in-house.
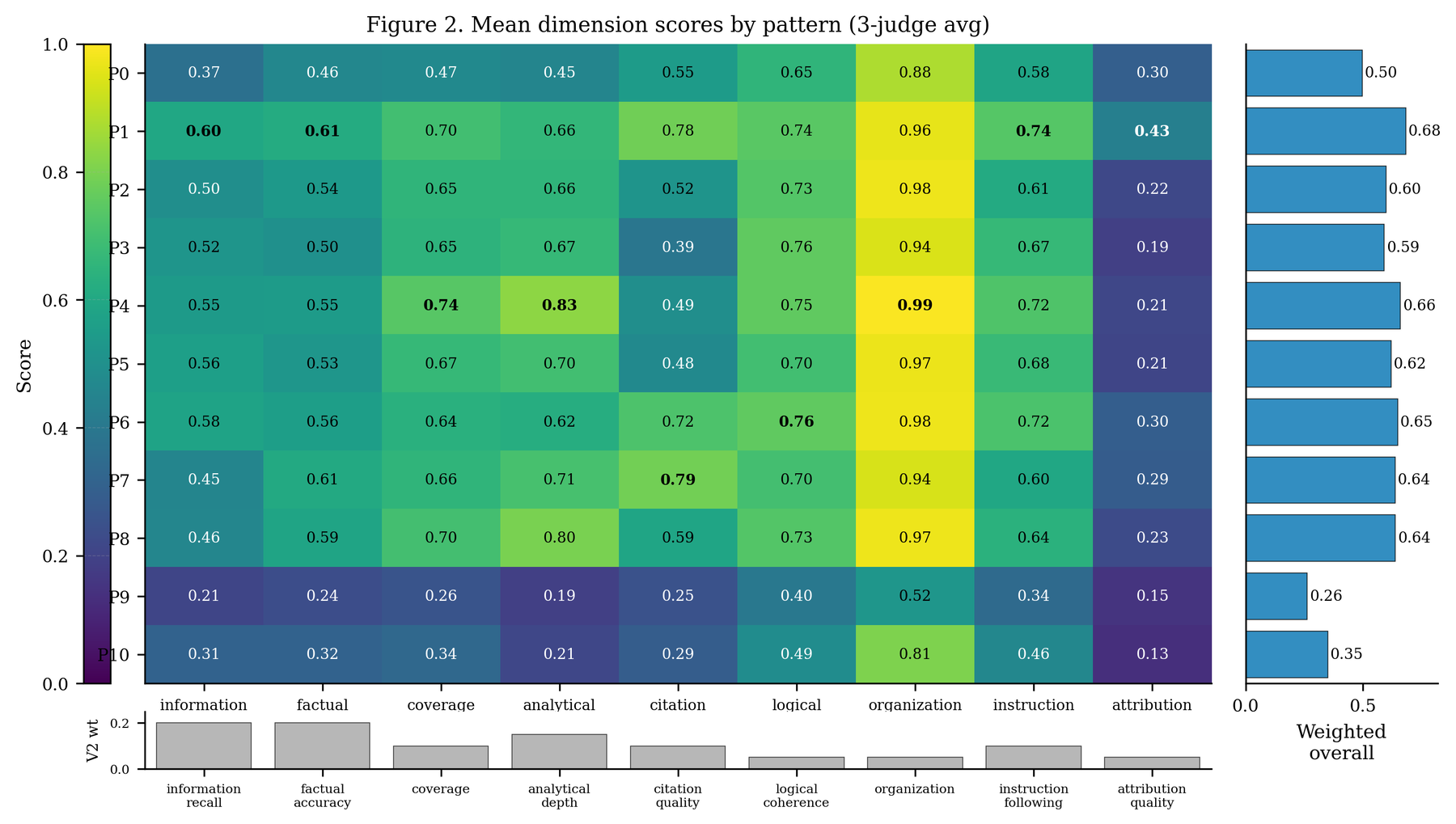
Every report is scored by a panel of three frontier judges from deliberately different model families, across a nine-dimension rubric with 38 binary criteria. Using three families is what lets the study isolate one variable at a time: baseline-versus-the-rest isolates orchestration, the 7B-versus-GPT-4o contrast isolates model scale, and trained-versus-untrained isolates RL.
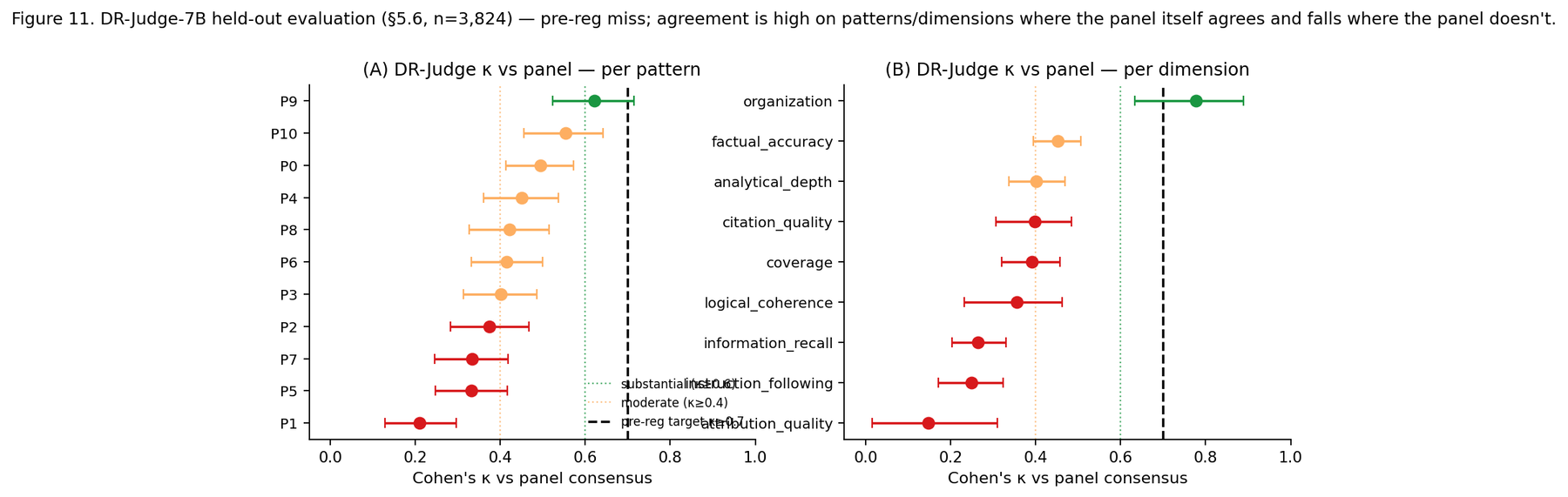
Before comparing a single architecture, the panel itself had to be validated — a benchmark scored by unreliable judges is just an opinion with error bars. The judges agreed well on style-shaped dimensions like organisation and badly on substance-shaped ones like factual accuracy and attribution; on attribution they agreed worse than chance. That split is not noise to average away. It means the panel can certify relative rankings and cluster equivalence, but not exact dimension-level scores to three decimals on the substantive dimensions. Every number below is read in that light. (The agreement statistics are in the methods section.)
A top cluster, not a winner
The headline architecture result is less dramatic than a leaderboard, and more useful.
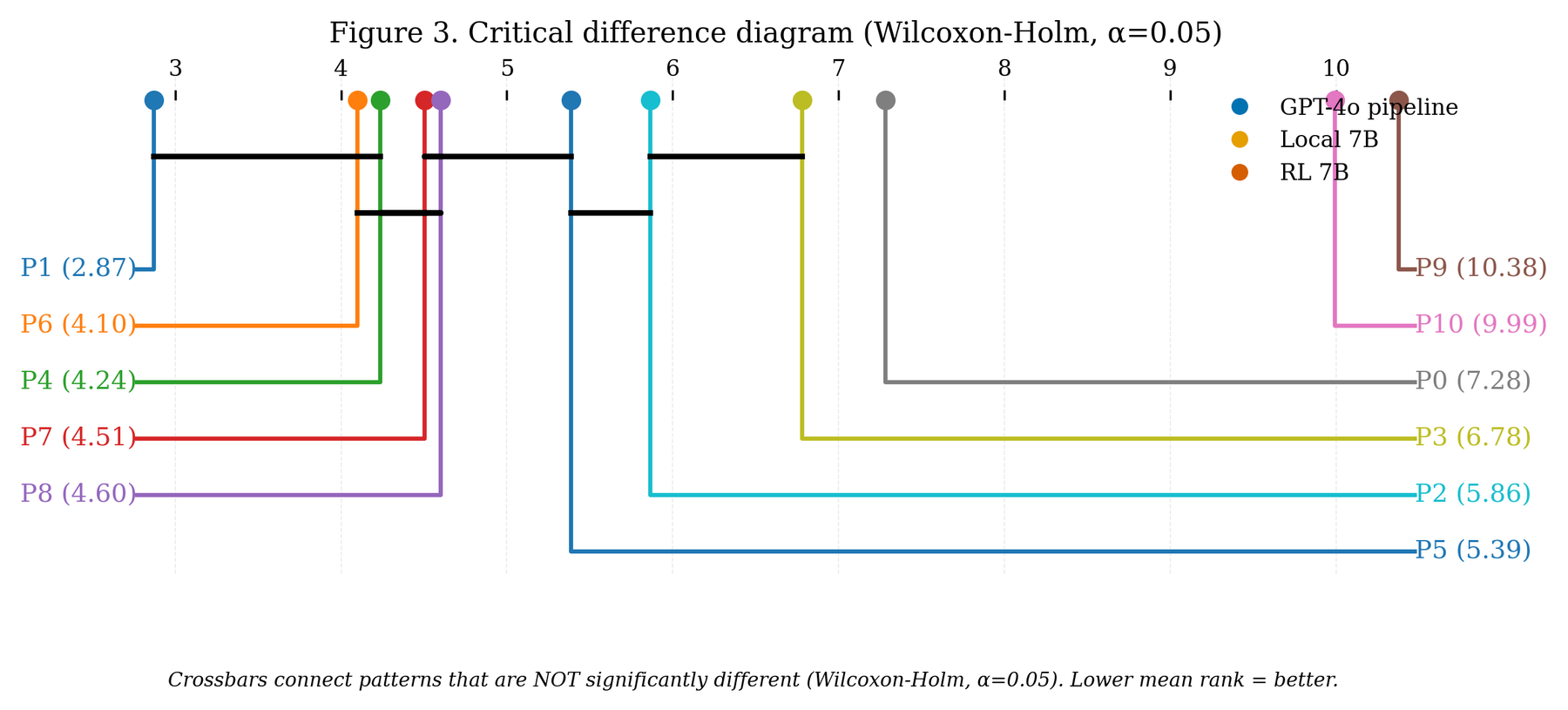
Six GPT-4o pipelines formed a statistically indistinguishable top cluster — iterative RAG, STORM, hierarchical width-and-depth, reactive interleaving, graph decomposition, and beam search. Their mean scores sat in a band narrow enough that ordering them would be reading noise as signal. To make "indistinguishable" precise, the study used equivalence testing rather than ordinary significance testing: it asked "are these two architectures equivalent within a margin declared in advance?", a question that can return a real positive answer, and most of the within-cluster pairs came back formally equivalent.
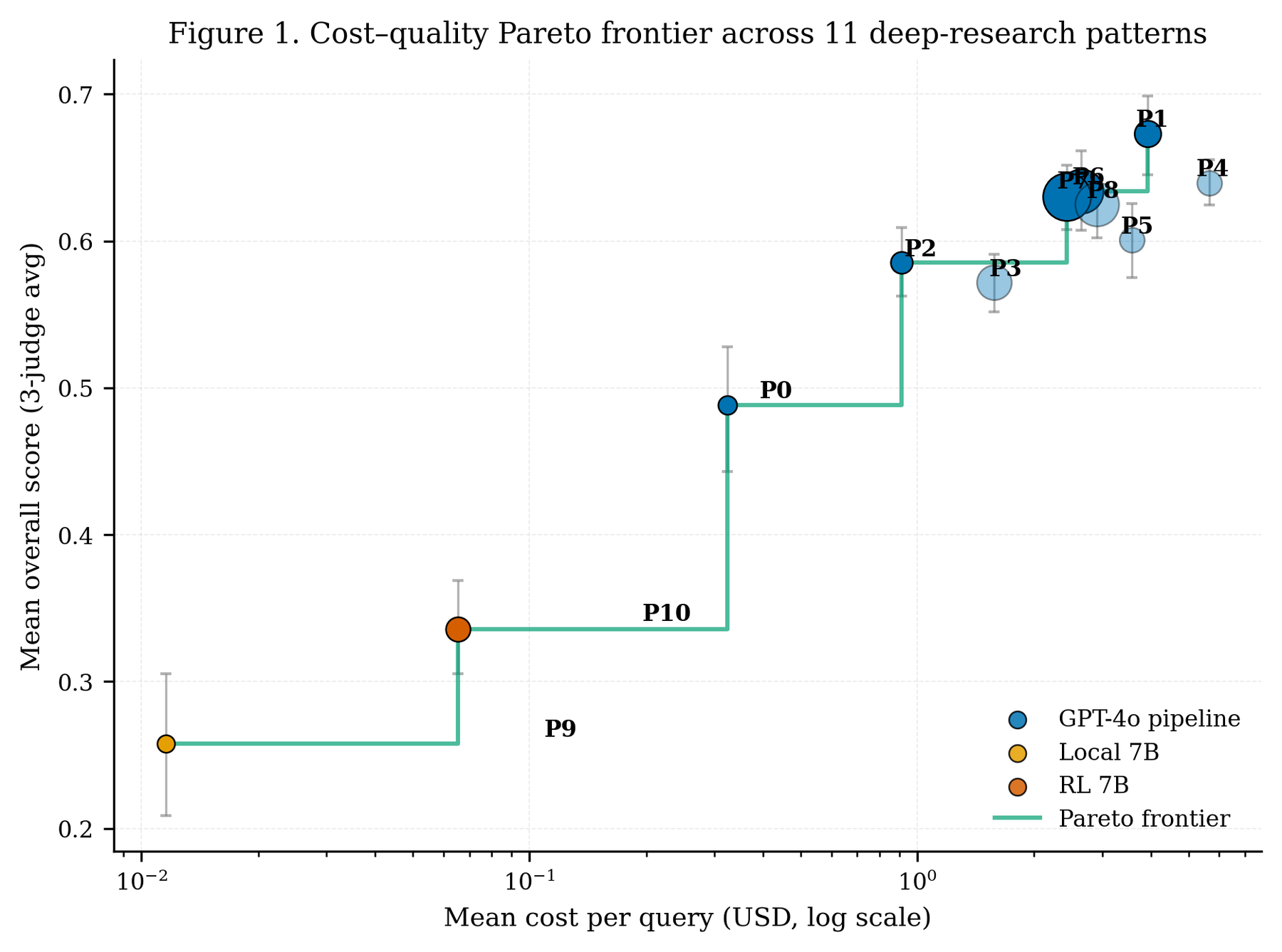
Here is what that buys you in practice. Orchestration was not cosmetic — the single-pass baseline never reached the top cluster, so some structure pays off. But once a system had enough retrieval and synthesis scaffolding to be competent, more elaborate orchestration stopped buying reliable gains. Plotting score against compute cost, the top cluster occupies a roughly 4× cost band with no clear quality ordering inside it. You can pay four times as much for orchestration and land in the same place.
Model scale hit harder than architecture
If orchestration produced a soft, clustered result, model scale produced a blunt one. The gap between the GPT-4o pipelines and the local 7B systems was about twice the entire architecture span measured across the GPT-4o family — and by some anchorings closer to five times. The exact multiplier depends on which range you compare against, but the direction is not in doubt: in this setup, base-model capability dominated every architecture effect observed.
That does not make architecture irrelevant. The largest single component effect measured anywhere in the study was STORM's triangulation stage — removing it caused a robustly significant loss. Architecture has real, measurable effects; they just have to be reported as effect sizes, not leaderboard positions. And the failure modes differed by family in a telling way: GPT-4o systems failed by producing fluent, citation-shaped reports that still needed provenance checks, while 7B systems failed visibly, by producing nothing gradeable at all.
The citation problem was worse than the score showed
The most uncomfortable finding was not about any architecture. It was about citations, and about what the judges were actually rewarding.
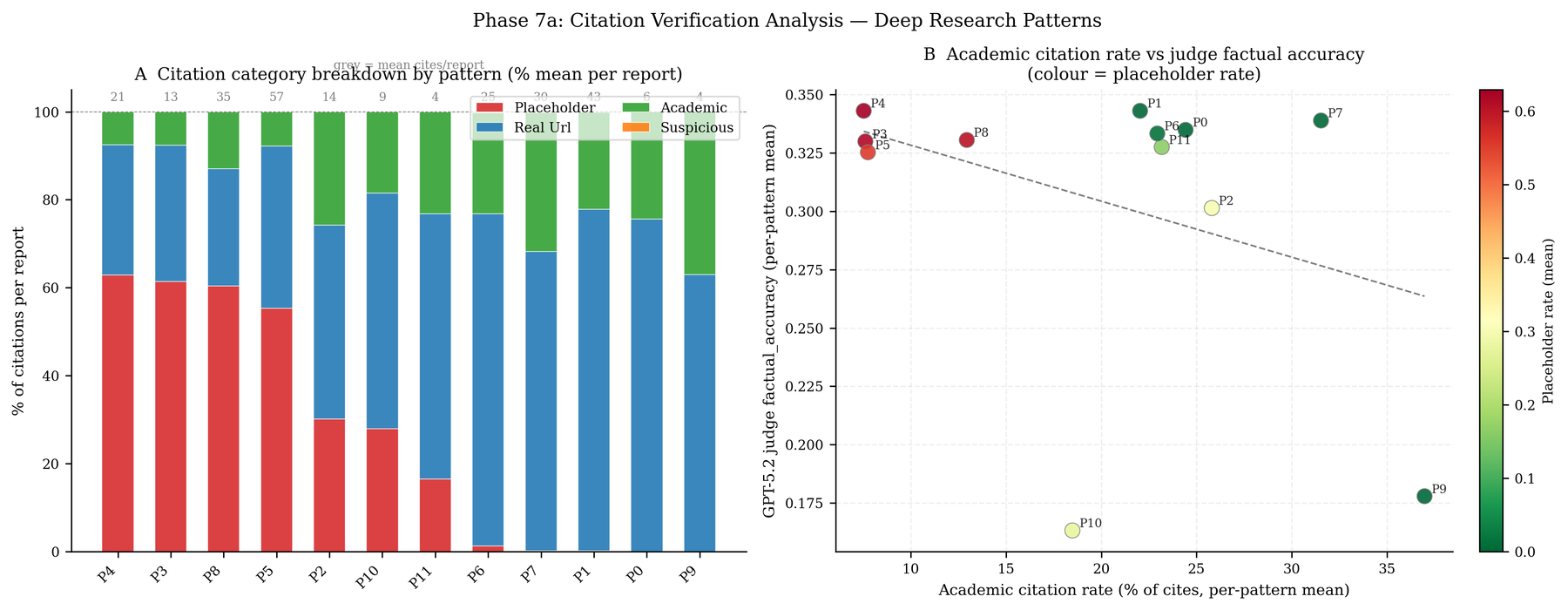
A provenance audit classified nearly 23,000 citations across the reports into placeholder, real-URL, academic, and malformed buckets. Several top-cluster patterns turned out to be citing mostly placeholders — text-only "Web Search Synthesis" strings rather than concrete URLs. STORM, the highest-scoring pattern overall, produced 62.9% placeholder citations. Three others sat above 55%. And the judges' citation-quality scores tracked citation density, not academic-source rate: a report with many bracketed references read as rigorous to the panel whether or not those references pointed anywhere. The judges were partly rewarding the appearance of grounding.
So the study ran a stricter test: decompose each report into atomic factual claims, resolve each inline citation against a URL cache, and ask whether the cited source directly supports the claim. Under that strict rubric, only 27% of claims were directly supported, just 0.5% were contradicted, and 69.5% landed in a neutral bucket — on-topic, but the source does not directly state the claim.
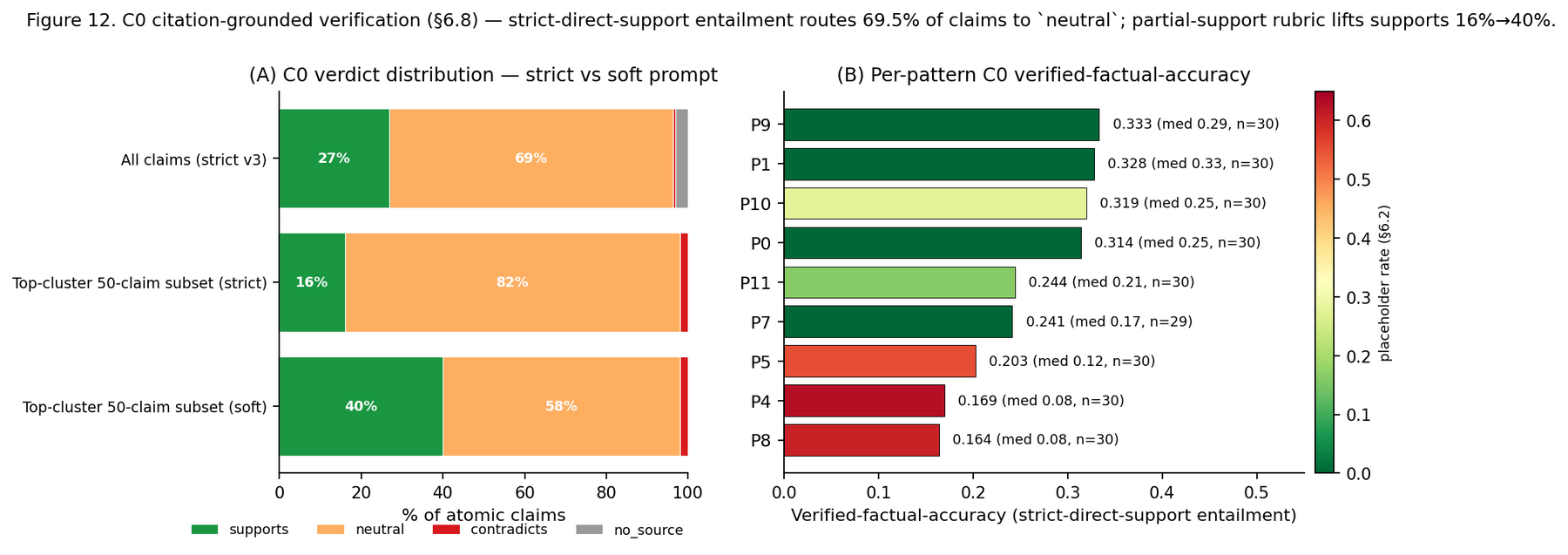
That 69.5% is easy to misread. The near-zero contradiction rate is reassuring: these reports rarely emit claims their own sources flatly refute. But the neutral mass is largely a measurement artefact, not a quality verdict. Deep-research reports synthesise — they combine and infer across multiple sources — and a rubric borrowed from short-form factuality checking, where atomic facts appear verbatim in one source, cannot score that. Re-running a sample under a rubric that admits multi-source triangulation lifted the "supports" rate substantially. Verification is not impossible here; it just needs a rubric built for synthesis.
The backend swap, the small judge, and the RL run
Three further experiments are worth keeping mostly because they refused to give clean answers.
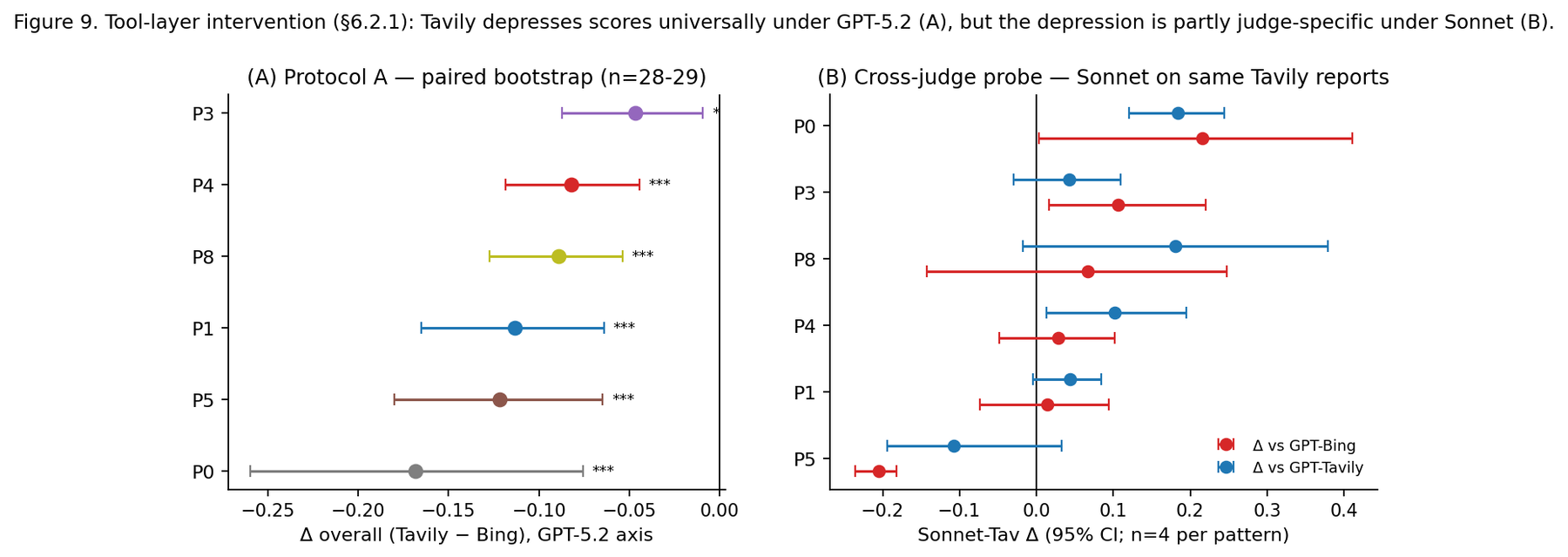
The backend swap made the story messier, not cleaner. A simple theory would be: replace the default web search with a backend that returns clean real URLs, and scores rise. Under one judge, the cleaner backend depressed scores across every pattern — because it returned far fewer citations, and some orchestration loops kept emitting synthesis text proportional to perspective count even when the retrieved evidence was thin. Under a different judge family, the effect mostly reversed. The naive "cleaner URLs, better scores" hypothesis was inverted by pattern-internal logic and by which judge you asked.
A small judge worked for the easy cases only. I fine-tuned a 7B model on panel-consensus verdicts to see whether a cheap local model could approximate the frontier panel. On verdicts where all three panel judges already agreed, it reached near-substantial agreement; on verdicts where the panel split, it collapsed. That makes it a useful triage layer, not a panel replacement — and it is a methodological point too: a model trained on majority labels learns the easy boundary and fails exactly where judgement is most valuable, because the tie-breaking logic is not in the labels.
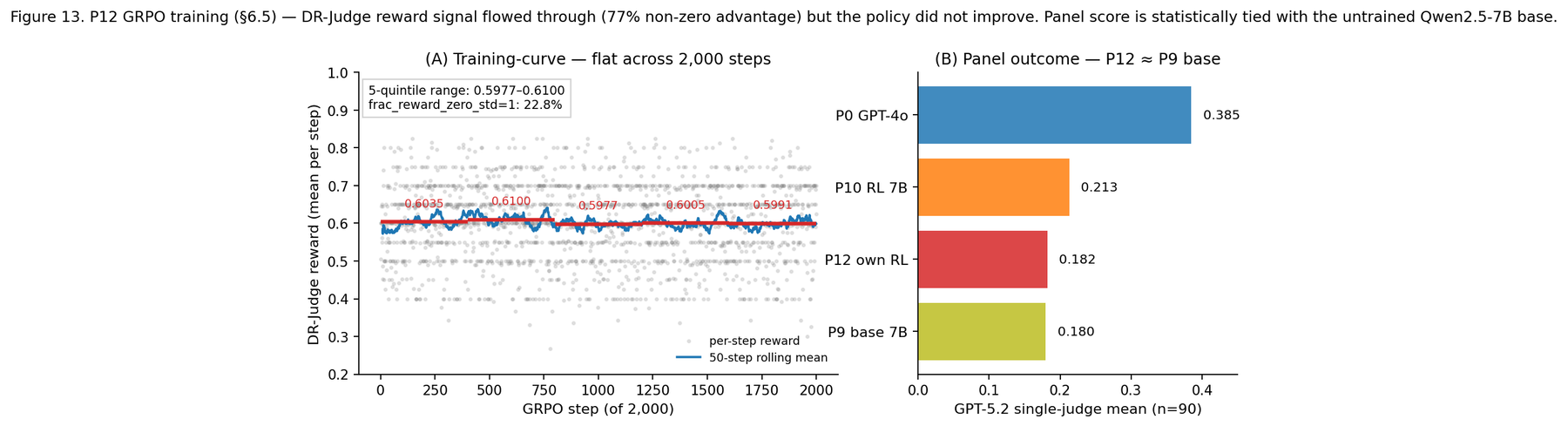
Training a research agent with RL, and watching it not improve. I RL-trained a 7B policy using that small judge as the reward model. The run completed, the reward signal had a gradient to follow — and the policy did not improve, scoring statistically tied with the untrained base. The bound matters: this is not an anti-RL claim. The study's own counter-evidence is a different 7B agent, trained with outcome supervision rather than rubric-judge supervision, that did beat its base. The reward-design axis mattered as much as the RL itself. A noisy judge does not make a useful reward model.
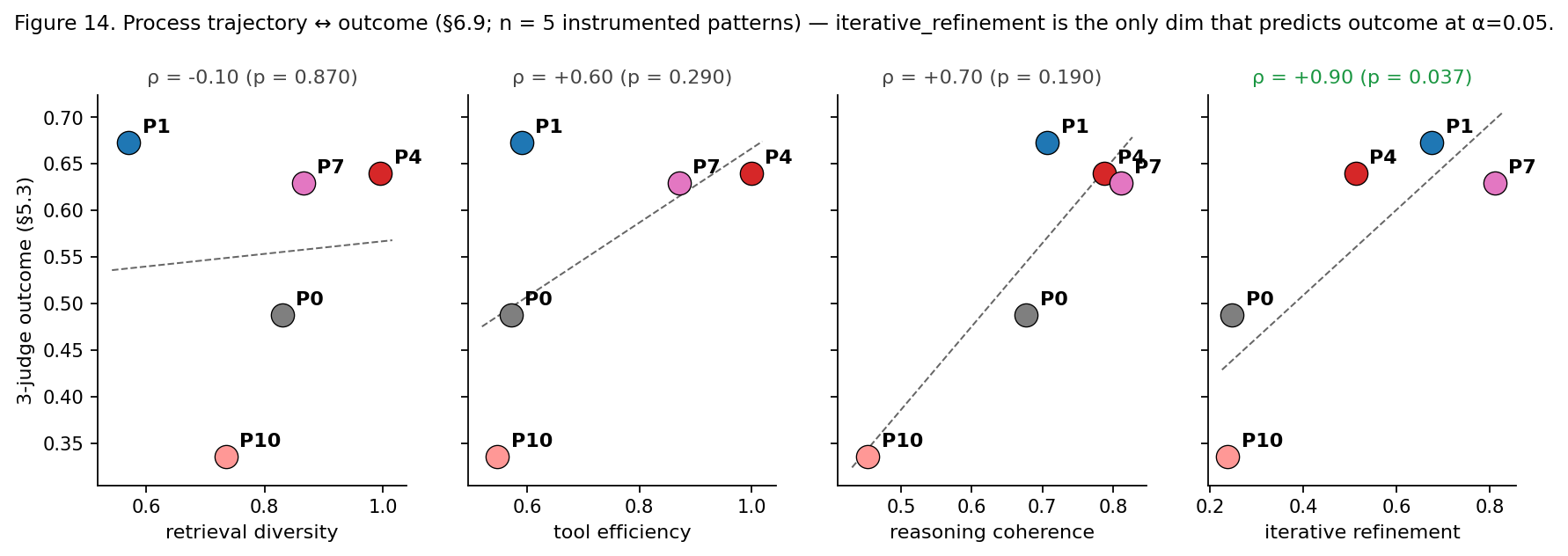
Process quality is not outcome quality
A trajectory audit scored four process dimensions against final outcome. Only one — whether the system revised its conclusions based on what it found — strongly predicted quality. Retrieval diversity was slightly anti-correlated with it.
That sounds strange until it connects back to the citation audit. More retrieval activity is not automatically better: more citation-shaped artefacts can mean more real evidence, or more surface area for impressive-looking placeholders. For agentic systems the design lesson is sharp — counting tool calls is not measuring research, and a trace is only worth instrumenting if it exposes whether the system actually changed its mind.
Everything above is the readable layer. The exact agreement coefficients, equivalence margins, entailment buckets, and effect sizes are below — skip them if you only wanted the conclusions.
The statistics, in full
Panel reliability was ICC(A,k=3) = 0.742 on the panel-averaged overall score — conventional "good" agreement — but Krippendorff's α (chosen because it handles missing verdicts and arbitrary scales) ranged from 0.840 on organisation down to −0.102 on attribution quality, with factual accuracy at 0.135 and information recall at 0.105. A negative α is agreement worse than chance; some rubric dimensions simply do not have a single answer a panel can converge on.
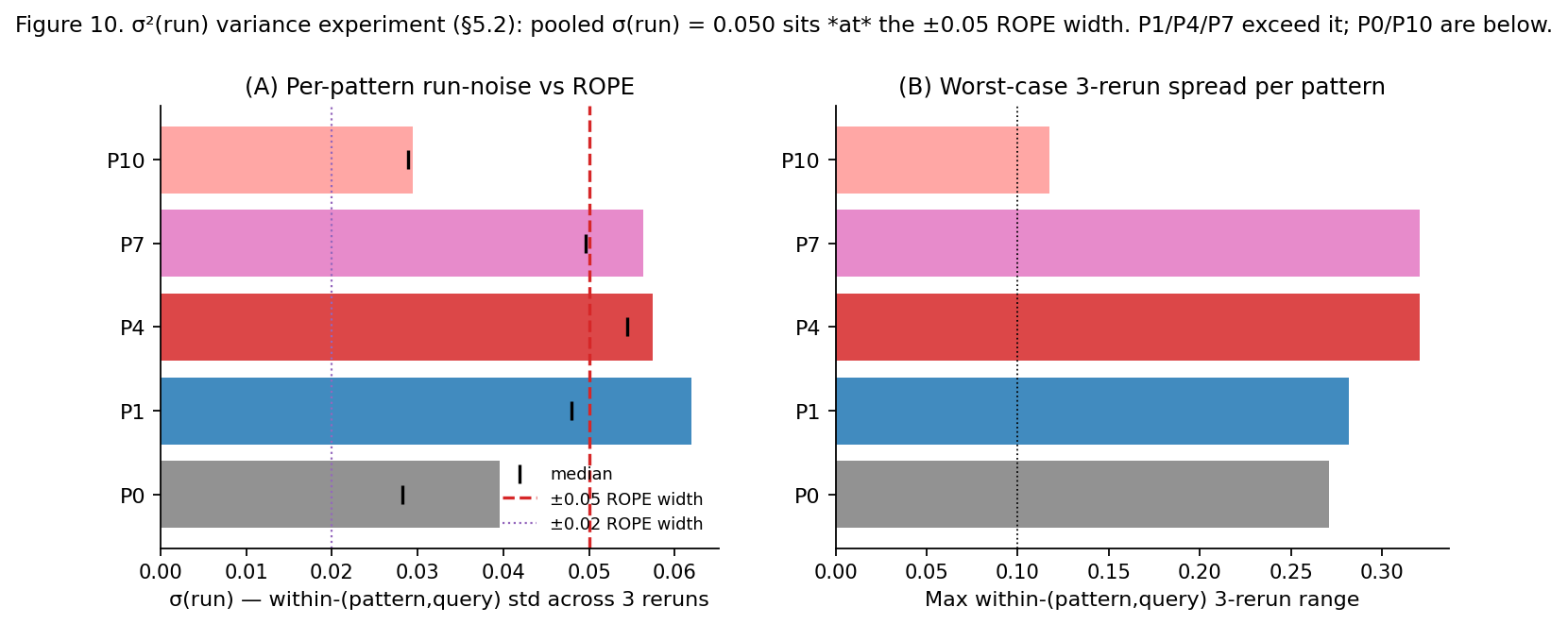
The six-pattern top cluster ran mean overall scores of 0.601–0.673. Under paired-Wilcoxon TOST at a ±0.05 region of practical equivalence, 9 of 15 pairs were formally equivalent; at a stricter ±0.02 ROPE, 0 of 15 were. The ±0.05 margin was matched to the design's minimum detectable effect (MDE₈₀ = 0.040), so the architectures are equivalent at the margin the data can resolve, no tighter. A run-variance probe put pooled run-to-run noise at σ(run) = 0.050 — the same size as the equivalence margin — which is why single-run pattern means should not be read to three decimals; the cluster claim rests on the full 90-query, three-judge design where paired averaging cancels much of that noise.
Model scale: the GPT-4o-versus-7B gap was about 0.40 in overall score. Against the baseline-to-top range within GPT-4o (0.185) that is ~2×; against the intra-orchestration range with the single-pass baseline excluded (0.072) it is ~5×. The single-pass baseline scored 0.488. STORM's triangulation ablation cost −0.060. A failure taxonomy over 49,442 unsatisfied criterion verdicts found citation fabrication 8× more common in GPT-4o pipelines (3.5% vs 0.4%) and empty-or-sparse output 7× more common in 7B systems (5.8% vs 0.8%).
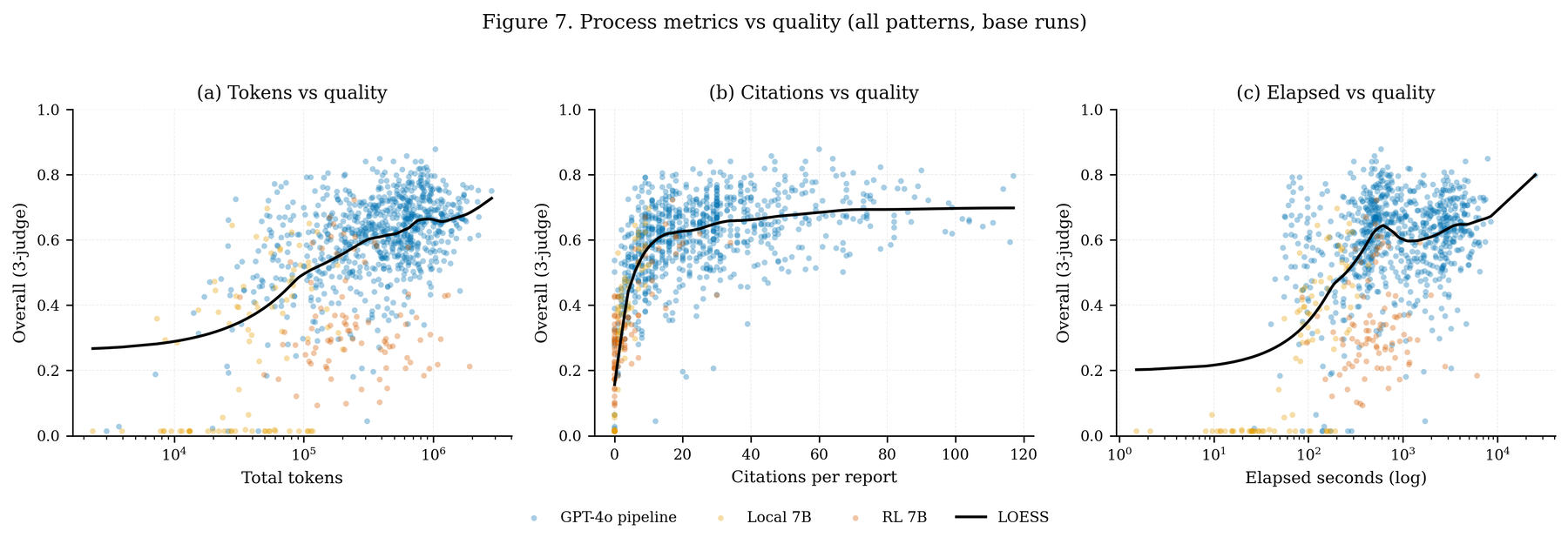
Citations: the provenance audit covered 22,903 citations; STORM 62.9% placeholder, topic-mining 61.4%, beam search 60.4%, hierarchical 55.3%, while iterative RAG, reactive interleaving, graph decomposition, and the baselines produced almost none. Judge citation-quality scores correlated with density (r = +0.28) but not academic-source rate (r = +0.01, n.s.); placeholder rate carried a small positive coefficient on factual-accuracy score (β = +0.026) even controlling for pattern, count, and length. The strict entailment pass: 26.8% supported, 0.5% contradicted, 69.5% neutral; a 50-claim re-run under a triangulation-aware rubric lifted "supports" from 16% to 40%.
The small judge reached Cohen's κ = 0.453 overall against the panel — 0.652 on undisputed verdicts, 0.199 on disputed — missing its pre-registered κ ≥ 0.7 target. The RL agent scored 0.182 versus 0.180 for the untrained base (tied); the outcome-supervised counter-example beat its base by Δ = 0.078. The process audit found iterative refinement predicted outcome at Spearman ρ = +0.90, retrieval diversity at ρ = −0.10.
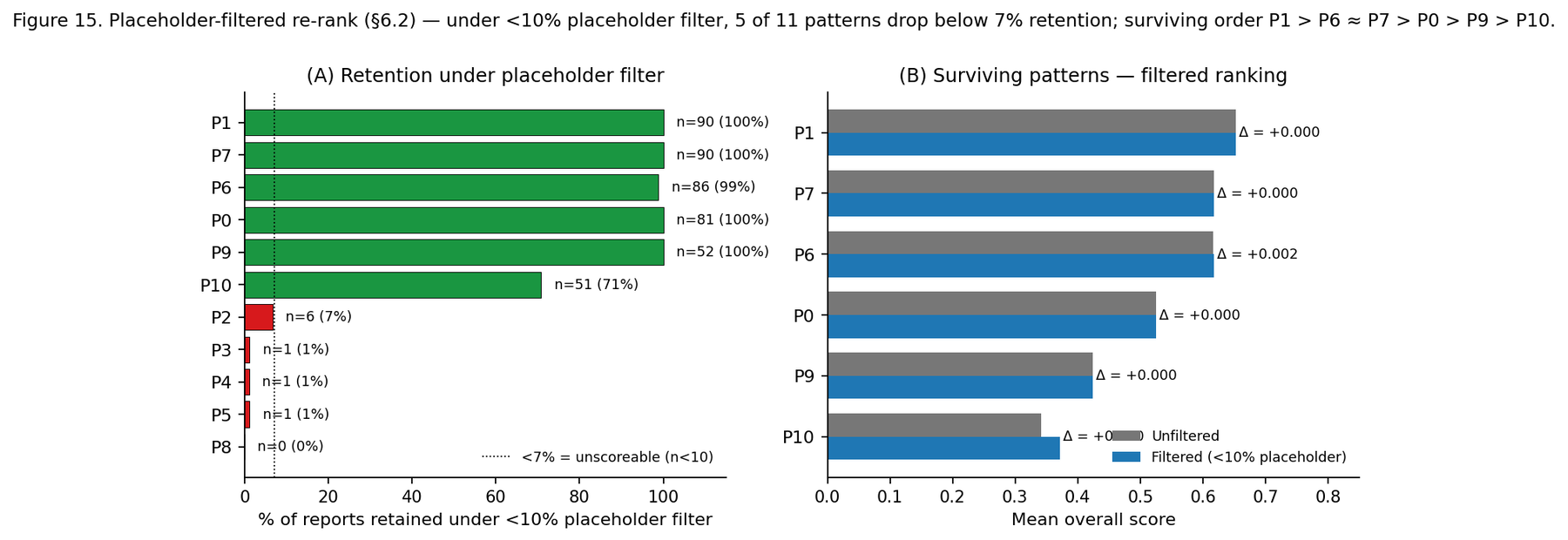
Limitations
- The retrieval bottleneck is inferred, not demonstrated. The tool layer was held constant across all patterns, so no intervention isolates retrieval as the binding constraint. An oracle-retrieval ablation would be needed to prove it; the thesis stays at "consistent with."
- Single tool layer, single query distribution — all English-language, Western-slanted. The results do not speak to multilingual, domain-restricted, or code-execution research.
- LLM-as-judge throughout. No human reference-rating pilot was run; within-judge re-test reliability and cross-version triangulation partly substitute, but neither establishes human ground truth.
- Substantive-dimension agreement is weak, so the panel certifies relative rankings and cluster equivalence, not exact substantive scores.
- The post-hoc patterns have thinner coverage — scored on one judge only, and the process audit instrumented just the patterns that emitted execution traces.
What to check before you trust your own agent
Strip away the machinery and the result is plain: once a deep-research system is competent, the architecture you pick matters less than you expect, the base model matters more, and the citation layer matters in a way the quality score never showed. Six pipelines tied for the top, and the highest scorer among them was citing 62.9% placeholders that the judges rewarded as rigour.
That last number is the one to act on. Take the deep-research agent you already run and audit its citations the way this study did — classify each into placeholder text, real URL, and academic source, then check what fraction of its claims a cited page actually supports. If your judge or your dashboard is rewarding bracket density rather than grounding, you will find it in an afternoon, and you will trust your own quality scores a little less and your provenance check a lot more. The architecture is the part everyone argues about. What the system cites is the part that turned out to matter.